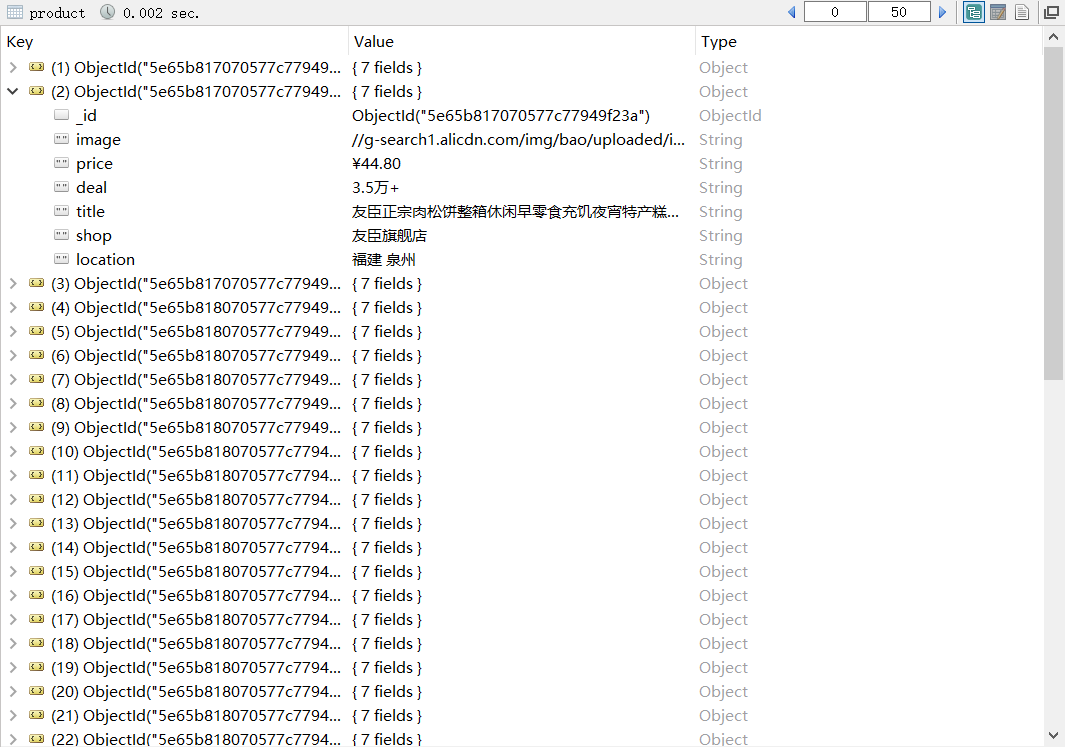
Python用selenium爬取淘宝美食信息
先奉上代码:# 如果使用PhantomJS则selenium版本只能2.48.0及以下 from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdrive...
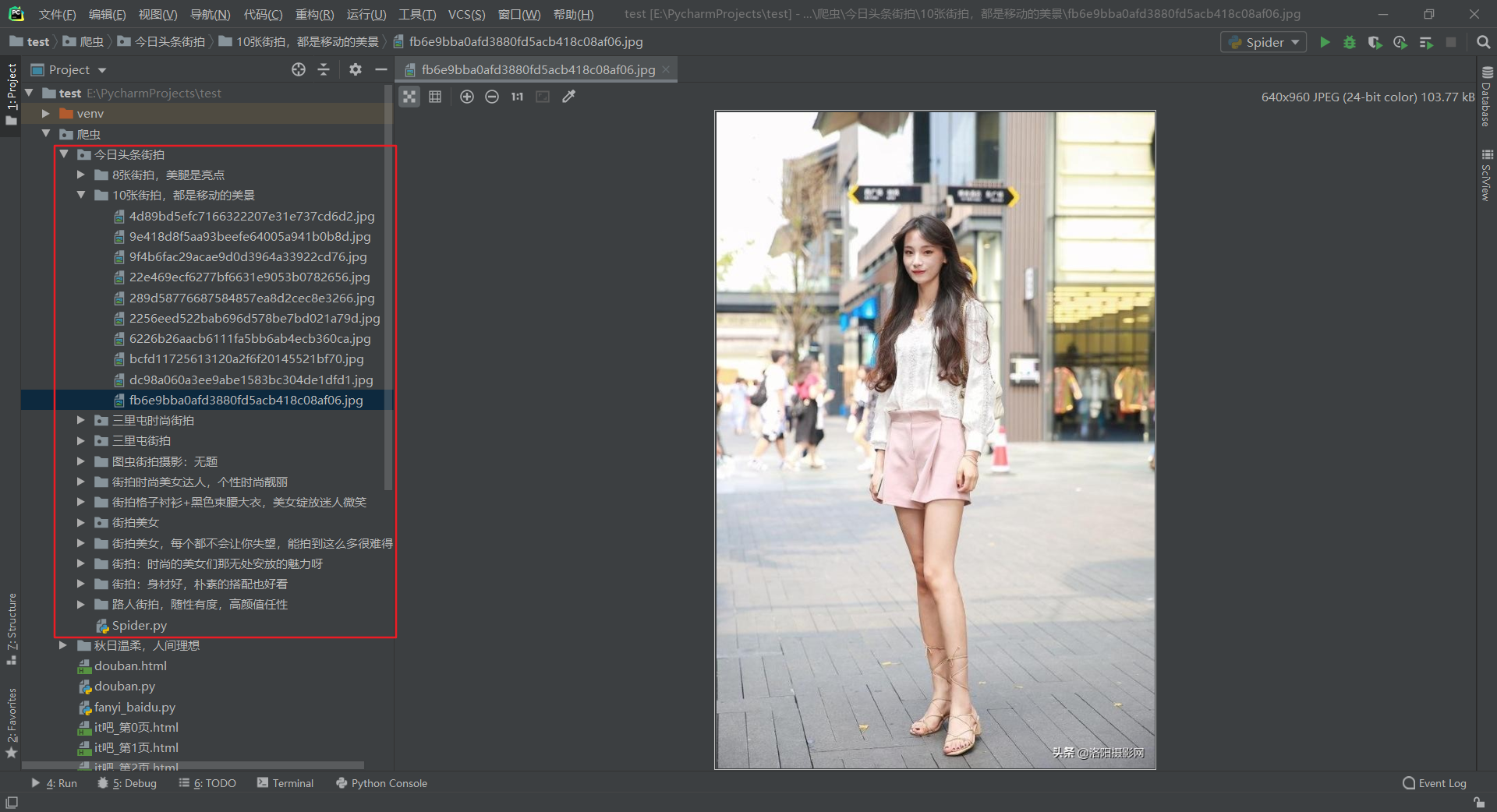
Python分析Ajax请求抓取今日头条街拍美图
结果如下:程序运行结果"C:\Program Files\Python\Python38\python.exe" E:/PycharmProjects/test/爬虫/今日头条街拍/Spider.py 请求文章详情页出错 None 正在下载1d47b4dceb635bff92ef296ce530cdc2.jpg 正在下载bff2d27b1d4ed77cc0a575513b...

Python用正则爬取猫眼之Top100榜的电影信息
爬取信息的主要出处</dd> <dd> <i class="board-index board-index-2">2</i> <a href="/films/1297" title="肖申克的救赎&qu...

Python用正则爬取豆瓣读书之新书速递的书籍信息
新书速递的书籍信息数据的主要采集出处<li class=""> <div class="cover"> <a href="https://book.douban.com/subject/34863428/?icn=index-latestbook-subject...

Python爬取豆瓣读书Top100的书籍信息
爬取豆瓣读书Top100的书籍信息(实则只有79本书)import requests import json from lxml import etree import re import time class Spider: def __init__(self): self.url_temp = 'https://www.douban.com/doulist/11...